
Artículo de Carlos Palomares
Apache Spark es un framework de procesamiento de big data de código abierto construido en torno a la velocidad, facilidad de uso y análisis sofisticado. Originalmente fue desarrollado en 2009 en AMPLab de UC Berkeley, y fue publicado en 2010 como un proyecto Apache.Spark tiene varias ventajas en comparación con otros frameworks big data y tecnologías como MapReduce de Hadoop y Storm.
En primer lugar, Spark nos brinda un marco completo y unificado para gestionar los requisitos de procesamiento de big data con una variedad de conjuntos de datos de naturaleza diversa (datos de texto, datos de gráficos, etc.) y las fuentes de datos.
Spark permite que las aplicaciones en los clústeres Hadoop se ejecuten hasta 100 veces más rápido en memoria y 10 veces más rápido incluso que cuando se ejecutan en el disco.
Spark te permite escribir aplicaciones rápidamente en Java, Scala o Python. Viene con un conjunto integrado de más de 80 conectores de alto nivel. Y puedes usarlo de forma interactiva para consultar datos dentro de su propia shell.
Además de las operaciones de Map-Reduce, admite consultas SQL, transmisión de datos, aprendizaje automático y procesamiento de datos de gráficos. Los desarrolladores pueden usar estas capacidades de forma independiente o combinarlas para ejecutarlas en un único caso de uso.
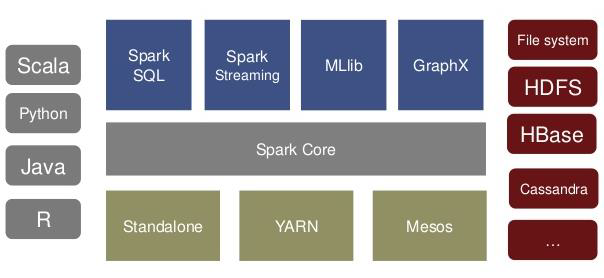
Además de Spark Core API, hay bibliotecas adicionales que son parte del ecosistema Spark y proporcionan capacidades adicionales en análisis Big Data y áreas de Machine Learning.
Estas bibliotecas incluyen:
Spark Streaming:
Spark Streaming se puede utilizar para procesar datos en tiempo real. Esto se basa en el procesamiento por micro-batching. Utiliza DStream, que es básicamente una serie de RDD, para procesar los datos en tiempo real. Desde SBD como conocedor y experto de esta tecnología, ofrecemos experiencia en diferentes casos de uso para la misma, principalmente para el análisis de impacto en clientes, en tiempo real permitiendo a negocio tomar decisiones inmediatas.

Spark SQL:
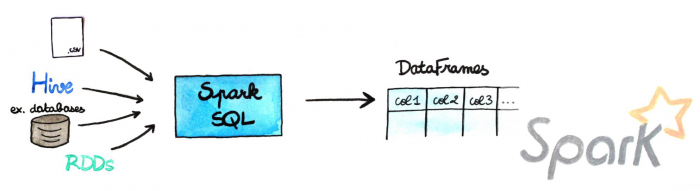
Spark SQL proporciona la capacidad de exponer los conjuntos de datos Spark sobre la API JDBC y permite ejecutar las consultas similares a SQL en datos Spark utilizando herramientas tradicionales de BI y visualización. Spark SQL permite a los usuarios transferir sus datos de ETL desde diferentes formatos en los que se encuentra actualmente (como JSON, Parquet, una base de datos), transformarlos y exponerlos para realizar consultas ad-hoc. Desde SBD tenemos amplia experiencia con esta biblioteca debido a que es la que permite a los equipos de BI de cualquier empresa, introducirse en el procesamiento Big Data.
Spark MLlib:
MLlib es la biblioteca de aprendizaje de máquina escalable de Spark que consiste en algoritmos y utilidades de aprendizaje comunes, que incluyen clasificación, regresión, clustering, filtrado colaborativo, reducción de dimensión, así como primitivas de optimización subyacentes. Desde el equipo de SBD de Data science utilizamos esta tecnología cuando el entrenamiento del modelo es tan exigente que necesitamos alta capacidad de procesamiento.
Spark GraphX:
GraphX es la nueva API Spark para gráficos y cómputo paralelo a gráficos. En un nivel alto, GraphX amplía el Spark RDD al introducir el Gráfico de Propiedad Distribuida Resistente: un multi-gráfico dirigido con propiedades asociadas a cada vértice y borde. Para admitir el cálculo de gráficos, GraphX expone un conjunto de operadores fundamentales (por ejemplo, subgraph, joinVertices y aggregateMessages), así como una variante optimizada de Pregel API. Además, GraphX incluye una creciente colección de algoritmos y constructores de gráficos para simplificar las tareas de análisis de gráficos.
Desde SBD siempre recomendamos el uso de Spark como framework principal de procesamiento Big Data, frente a Hadoop u otros debido a entre otras razones:
• Spark corre sobre ecosistema Hadoop, son complementarios.
• El modelo de programación de Spark es más flexible que el de Hadoop.
• Spark ofrece una gran mejora si los datos caben en memoria (~100 GB).
• El almacenamiento en Spark es agnóstico al sistema distribuido de almacenamiento utilizado.
• Spark es “más sencillo” que Hadoop.
• Tiene una interfaz mas “amigable” para científicos de datos o analistas.
• El API soporta múltiples lenguajes.