
La trazabilidad de datos es uno de los principales quebraderos de cabeza de las grandes empresas. Las razones que empujan a contar con esta necesidad no sólo es asegurarse una fácil localización de errores que haga más sencillo su corrección, sino que también tiene mucho que ver con las normativas legales, que cada vez son más, y que exigen controlar y conocer la trazabilidad de los datos.
Además, dado que los datos son un activo particularmente estratégico y valioso, una trazabilidad efectiva ayuda a mantener el control sobre los tratamientos que se realizan.
Idealmente, las herramientas de trazabilidad de datos deberían poder rastrear las versiones de los conjuntos de datos utilizados. De hecho, dentro del contexto del DataLake donde las fuentes de datos cambian con es muy importante poder rastrear qué versión del Dataset de entrada se utilizó para producir dicho Dataset de salida.
¿Cuáles son las herramientas existentes?
Existen distintas herramientas para realizar esta trazabilidad, algunas de las cuales son más o menos específicas, más o menos globales, relacionadas con los ecosistemas de Big Data o no:
- Herramientas para hacer la trazabilidad en los sistemas de almacenamiento de datos donde todos los datos están estructurados, es decir, el código se encuentra escrito en SQL. Por ejemplo QueryFlow.
- También hay muchas más macroherramientas que hacen posible mapear los datos, asegurar el gobierno de los datos, etc. Por ejemplo están Collibra o Zeenea , especializadas en el mapeo de datos y el catálogo de datos.
- Dentro del mundo del Big Data, hay dos herramientas que permiten establecer la trazabilidad de los datos: Apache Atlas o Cloudera Navigator. Estas herramientas son bastante nuevas y ofrecen una granularidad de trazabilidad relativamente alta con el control de versiones inexistente de los conjuntos de datos. Además, estas herramientas interfieren mal con Apache Spark, que se ha convertido en el marco de procesamiento de los datos más populares y tienden a verlo como una caja negra. Sin embargo, Apache Atlas ofrece una API de trazabilidad que se puede invocar directamente desde el procesamiento Spark.Apache Nifi propone una función de "Repositorio de procedencias" para hacer trazabilidad en los datos ingestados.
- Finalmente, hay herramientas específicas para Spark que permiten hacer la trazabilidad automáticamente con una granularidad más fina. Esta herramienta se llama Spline . Spline proviene de Spark Lineage y se compone de dos elementos: un kernel que permite deducir las diferentes transformaciones y una interfaz de usuario web para visualizar el resultado de los trabajos. Es una herramienta relativamente joven desarrollada por el banco sudafricano Absa.
Spline es una herramienta desarrollada por un banco sudafricano para cumplir con el estándar bancario BCBS 239 (norma de contabilidad regulatoria sobre gestión de riesgos financieros e informes). Para realizar la trazabilidad, Spline se basa en el plan de ejecución de Spark generado automáticamente por el marco.
El plan de ejecución consiste en todas las operaciones que se realizarán en un trabajo Spark (secuencia de acciones o transformaciones, como filter, joins, group by, etc.). Hay dos planos de ejecución: el plano lógico que se compone de las instrucciones en el orden en que aparecen en el código, y el plano físico que optimiza el orden de las diferentes instrucciones. Spline se basa en la lógica porque es la secuencia de acciones que nos interesa.
Spline cuenta con diferentes back-end para el almacenamiento de datos: MongoDB, HDFS o Apache Atlas. Para la demostración de esta herramienta, utilizaremos MongoDB .
Instalando MongoDB
Para comenzar, lanzaremos un contenedor Docker que contiene la base de datos MongoDB . Para esto, nada más simple, ejecute el siguiente comando:
> docker run -it -p 27017:27017 -d mongo:3.4
> docker exec -it [conatiner_name] mongo
Si el shell se ejecuta sin error y la sentencia show dbs lista las bases de datos predeterminadas, se habrá instalado correctamente MongoDB.
Instalación de spline
Para instalar Spline tendremos que clonarnos la rama de GitHub de este proyecto: https://github.com/AbsaOSS/spline.git
Lanzamos un mvn install -DskipTests dentro de la carpeta spline/web y dentro del target se generará el jar necesario para lanzar la interfaz de usuario de Spline.
Lanzar Spline
Podemos iniciar el servidor web con el siguiente comando especificando bien la URL de la base MongoDB (localhost en nuestro caso) y el nombre de la base de datos mongo donde queremos registrar la información (local por defecto).
>java -jar spline-ui-0.3.0.exec.jar -Dspline.mongodb.url=mongodb://localhost -Dspline.mongodb.name=local
Si todo va bien, la interfaz de usuario web debe estar accesible en http: // localhost: 8080 desde su navegador.
Lanzamiento de un job de Spark
Spline nos proporciona un ejemplo de jobs Spark para visualizar nuestra trazabilidad, pero obviamente es posible asociar Spline con sus jobs ya existentes (especificando bien la dependencia hacia MongoDB, Spark y Scala en el administrador de dependencias) al agregar WAR Spline a Classpath y agregando las siguientes dos líneas:
import za.co.absa.spline.core.SparkLineageInitializer._
sparkSession.enableLineageTracking()
Para este tutorial, utilizaremos los jobs de ejemplo proporcionados por Spline. Vaya a la carpeta de sample e inicie uno de los jobs con el siguiente comando:
mvn test -Psamples -Dspline.mongodb.url=mongodb://localhost -Dspline.mongodb.name=local -DsampleClass=za.co.absa.spline.sample.SampleJob1
Una vez ejecutado, vaya a http: // localhost: 8080 para ver los resultados del trabajo seleccionando el resultado a la izquierda y haciendo clic en "mostrar gráfico de trazabilidad" a la derecha.
Esto nos da una vista macroscópica de los tratamientos:
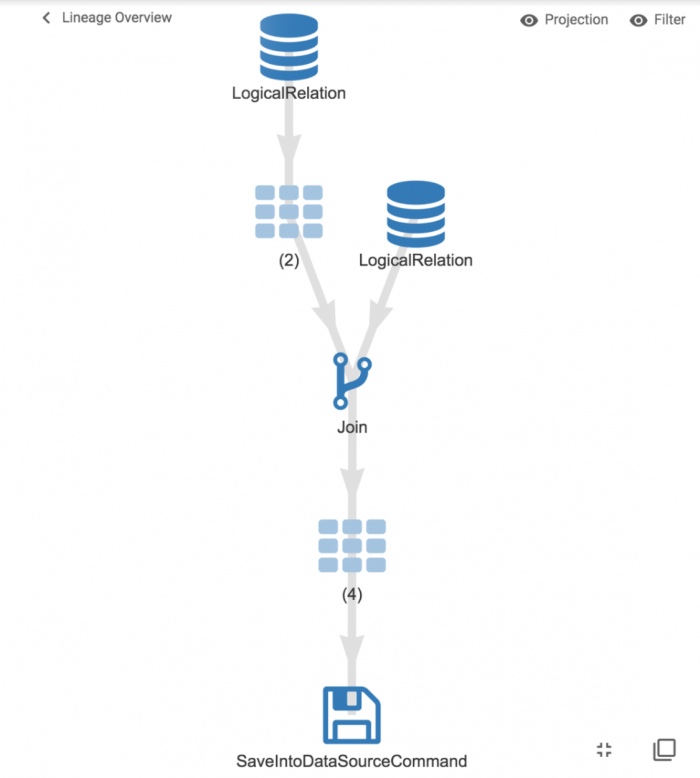
Es posible hacer clic donde se reúnen los tratamientos para obtener detalles sobre las operaciones:
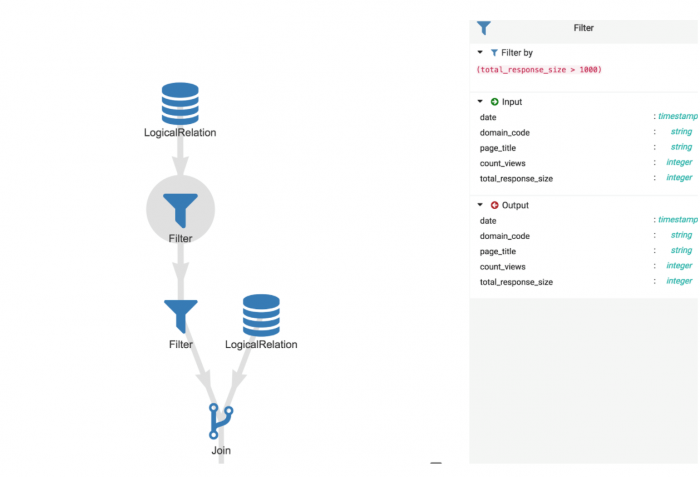
Por ejemplo, podemos ver el detalle del filtro que se ha realizado con los datos de entrada y salida y la condición de filtrado que se ha aplicado.
Limitaciones / Conclusión
Como hemos visto, Spline es muy fácil de usar y facilita el inicio de la trazabilidad en los jobs Spark. Entre otras cosas, puede documentar la lógica comercial y se puede usar para ayudar a monitorear el desempeño del job identificando la duración de cada paso.
Sin embargo, la desventaja de Spline (y todas las herramientas de trazabilidad en Spark en general) es que funciona muy bien siempre que usemos DataFrames API y Spark SQL (porque un plan de se genera una ejecución detallada), pero cuando salimos de esta API para desarrollos más específicos (uso de map DataFrames y cambio al Dataset de API), Spline no puede saber qué está sucediendo dentro de esto map se interpreta como un recuadro negro.
Sin embargo, en "condiciones reales", uno se ve obligado a abandonar DataFrames con frecuencia para realizar desarrollos específicos al pasar a través de conjuntos de datos.
Aparte de eso, Spline es una herramienta fácil de usar con una interfaz de usuario de calidad que permite a los desarrolladores y empresas compartir e interactuar de forma común. Spline es una herramienta todavía joven que mejorará y enriquecerá las nuevas características a lo largo del tiempo (Spark Streaming, mejor versión de IO, administrador de usuarios que lanza trabajos ...).